
介紹 Gemma 3n:Google 的下一代 AI 模型
谷歌發布了 Gemma 3n,這是其一系列開放式 AI 模型的革命性進步。該新版本在上個月的 Google I/O 大會上亮相,現已全面開放給開發者在本地硬體上實現。
對於不熟悉 Gemma 系列的人來說,它與Google專有的 Gemini 型號截然不同。 Gemma 的設計理念是開源,允許開發者自由下載、修改和創新;而 Gemini 則是一個專注於高效能任務的封閉平台。
Gemma 3n 的主要特點
最新版本的 Gemma 3n 標誌著重大的進化,因為它支援多種輸入類型,包括圖像、音頻和視頻,並產生文字輸出。這種多模態功能與先前純文字模型相比,帶來了顯著的轉變。以下是此模型引入的突出增強功能:
- 多模式功能: Gemma 3n 無縫整合文字、圖像、音訊和視訊輸入,增強了使用者互動的多功能性。
- 設備上最佳化:此模型的兩個變體 E2B 和 E4B 均針對效率進行了最佳化,能夠在佔用極少記憶體的硬體上高效運作。 E2B 的參數數量為 50 億,E4B 的參數數量為 80 億,但運行時的記憶體佔用卻與僅佔用 2GB RAM(E2B)和 3GB RAM(E4B)的傳統模型相似。
- 創新架構: Gemma 3n 的核心採用名為 MatFormer 的先進架構,可提供運算彈性。該結構包含逐層嵌入 (PLE),可提高記憶體利用率,並配備專為行動應用量身定制的全新音訊和 MobileNet-v5 視覺編碼器。
- 卓越品質:該模型提高了輸出質量,支援 140 種語言的文本多語言交互和 35 種語言的多模式任務多語言交互,同時提高了數學、編碼和邏輯推理方面的性能。
Gemma 3n 的高效性源自於其 MatFormer 架構。谷歌將其比作俄羅斯娃娃,較大的模型內部包裹著更小、功能齊全的版本,以適應各種任務。
在性能基準測試中,E4B 變體的 LMArena 得分顯著超過 1300,這標誌著它成為第一個在 100 億參數以下達到這一里程碑的模型。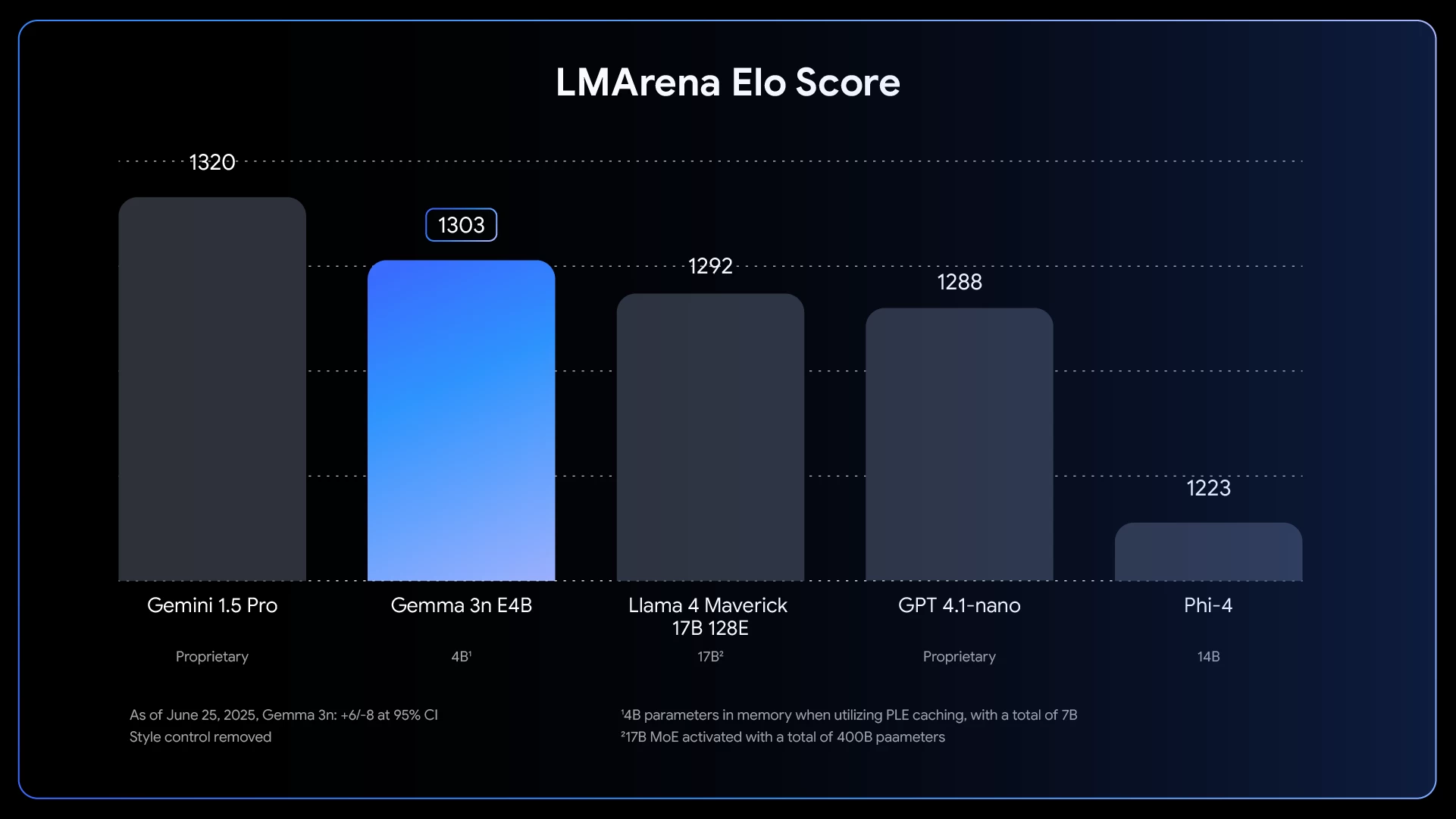
先進的音訊和視訊功能
Gemma 3n 引入了增強的音訊功能,包括裝置上的語音轉文字和翻譯功能,並由能夠精確處理語音的編碼器提供支援。升級後的 MobileNet-V5 視覺編碼器顯著提升了視訊處理速度,可在 Google Pixel 裝置上以高達每秒 60 幀的速度即時播放影片。
開始使用 Gemma 3n
如果您渴望探索 Gemma 3n,可以透過 Hugging Face 和 Kaggle 等平台輕鬆存取模型,也可以在Google AI Studio中直接試驗其功能。
有關此模型的全面詳細資訊(包括開發人員指南),請查看官方公告貼文。



發佈留言