
介绍 Gemma 3n:Google 的下一代 AI 模型
谷歌发布了 Gemma 3n,这是其一系列开放式 AI 模型的革命性进步。该新版本在上个月的 Google I/O 大会上亮相,现已全面开放给开发者在本地硬件上实现。
对于不熟悉 Gemma 系列的人来说,它与谷歌专有的 Gemini 型号截然不同。Gemma 的设计理念是开源,允许开发者自由下载、修改和创新;而 Gemini 则是一个专注于高性能任务的封闭平台。
Gemma 3n 的主要特点
最新版本的 Gemma 3n 标志着一次重大的进化,因为它支持多种输入类型,包括图像、音频和视频,并生成文本输出。这种多模态功能与之前纯文本模型相比,带来了显著的转变。以下是该模型引入的突出增强功能:
- 多模式功能: Gemma 3n 无缝集成文本、图像、音频和视频输入,增强了用户交互的多功能性。
- 设备上优化:该模型的两个变体 E2B 和 E4B 均针对效率进行了优化,能够在占用极少内存的硬件上高效运行。E2B 的参数数量为 50 亿,E4B 的参数数量为 80 亿,但运行时的内存占用却与仅占用 2GB RAM(E2B)和 3GB RAM(E4B)的传统模型相似。
- 创新架构: Gemma 3n 的核心采用名为 MatFormer 的先进架构,可提供计算灵活性。该结构包含逐层嵌入 (PLE),可提高内存利用率,并配备专为移动应用量身定制的全新音频和 MobileNet-v5 视觉编码器。
- 卓越品质:该模型提高了输出质量,支持 140 种语言的文本多语言交互和 35 种语言的多模式任务多语言交互,同时提高了数学、编码和逻辑推理方面的性能。
Gemma 3n 的高效性源于其 MatFormer 架构。谷歌将其比作俄罗斯套娃,较大的模型内部包裹着更小、功能齐全的版本,以适应各种任务。
在性能基准测试中,E4B 变体的 LMArena 得分显著超过 1300,这标志着它成为第一个在 100 亿参数以下达到这一里程碑的模型。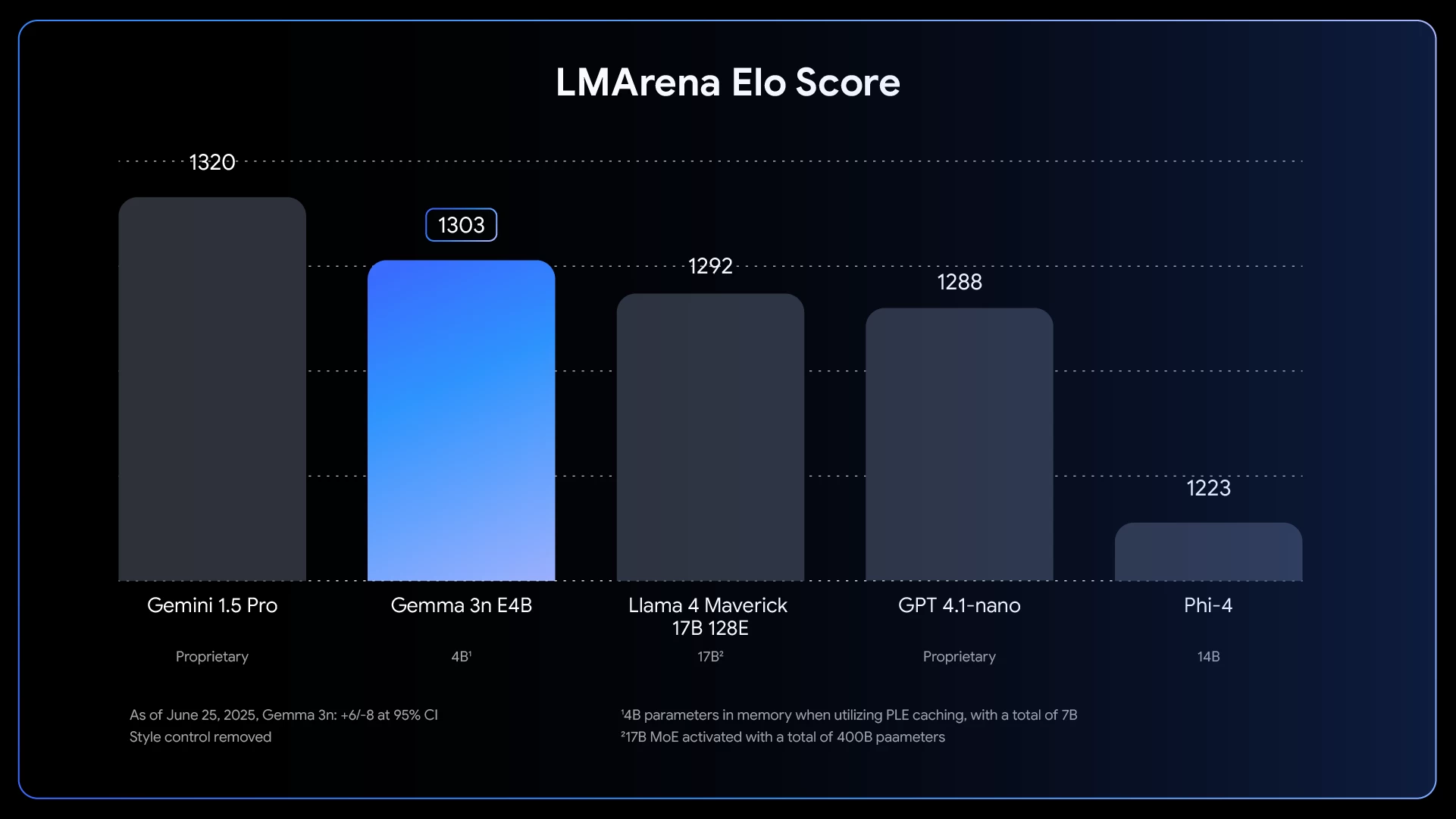
先进的音频和视频功能
Gemma 3n 引入了增强的音频功能,包括设备上的语音转文本和翻译功能,并由能够精确处理语音的编码器提供支持。升级后的 MobileNet-V5 视觉编码器显著提升了视频处理速度,可在 Google Pixel 设备上以高达每秒 60 帧的速度实时播放视频。
开始使用 Gemma 3n
如果您渴望探索 Gemma 3n,可以通过 Hugging Face 和 Kaggle 等平台轻松访问模型,也可以在Google AI Studio中直接试验其功能。
有关此模型的全面详细信息(包括开发人员指南),请查看官方公告帖子。



发表回复